



Abstract
We present two novel solutions for multi-view 3D human pose estimation based on new learnable triangulation methods that combine 3D information from multiple 2D views.
The first (baseline) solution is a basic differentiable algebraic triangulation with an addition of confidence weights estimated from the input images. The second, more complex, solution is based on volumetric aggregation of 2D feature maps from the 2D backbone followed by refinement via 3D convolutions that produce final 3D joint heatmaps.
Crucially, both of the approaches are end-to-end differentiable, which allows us to directly optimize the target metric. We demonstrate transferability of the solutions across datasets and considerably improve the multi-view state of the art on the Human3.6M dataset.
Results
- We conduct experiments on two available large multi-view datasets: Human3.6M [2] and CMU Panoptic [3]
- Main metric is MPJPE (Mean Per Joint Position Error) which is L2 distance averaged over all joints
Note: Here and further we report only summary of our results. Please refer to our paper [cite] for more details.
Human3.6M
- We surpassed previous state of the art [5] in ~2.4 times (error relative to pelvis)
- Our best model reaches 17.7 mm error in absolute coordinates, which is more than enough for real-life applications
- Our volumetric model is able to estimate 3D human pose using any number of cameras, even using only 1 camera. In single-view setup we get results comparable with current state of the art [6] (49.9 mm vs. 49.6 mm)
MPJPE relative to pelvis:
| MPJPE (averaged across all actions), mm | |
|---|---|
| Multi-View Martinez [4] | 57.0 |
| Pavlakos et al. [8] | 56.9 |
| Tome et al. [4] | 52.8 |
| Kadkhodamohammadi & Padoy [5] | 49.1 |
| RANSAC (our implementation) | 27.4 |
| Ours, algebraic | 22.6 |
| Ours, volumetric | 20.8 |
MPJPE absolute (filtered scenes with non-valid ground-truth annotations):
| MPJPE (averaged across all actions), mm | |
|---|---|
| RANSAC (our implementation) | 22.8 |
| Ours, algebraic | 19.2 |
| Ours, volumetric | 17.7 |
MPJPE relative to pelvis (single-view methods):
| MPJPE (averaged across all actions), mm | |
|---|---|
| Martinez et al. [7] | 62.9 |
| Sun et al. [6] | 49.6 |
| Ours, volumetric single view | 49.9 |
CMU Panoptic
- Our best model reaches 13.7 mm error in absolute coordinates for 4 cameras
- We managed to get much smoother and more accurate 3D pose annotations compared to dataset annotations (see video demonstration)
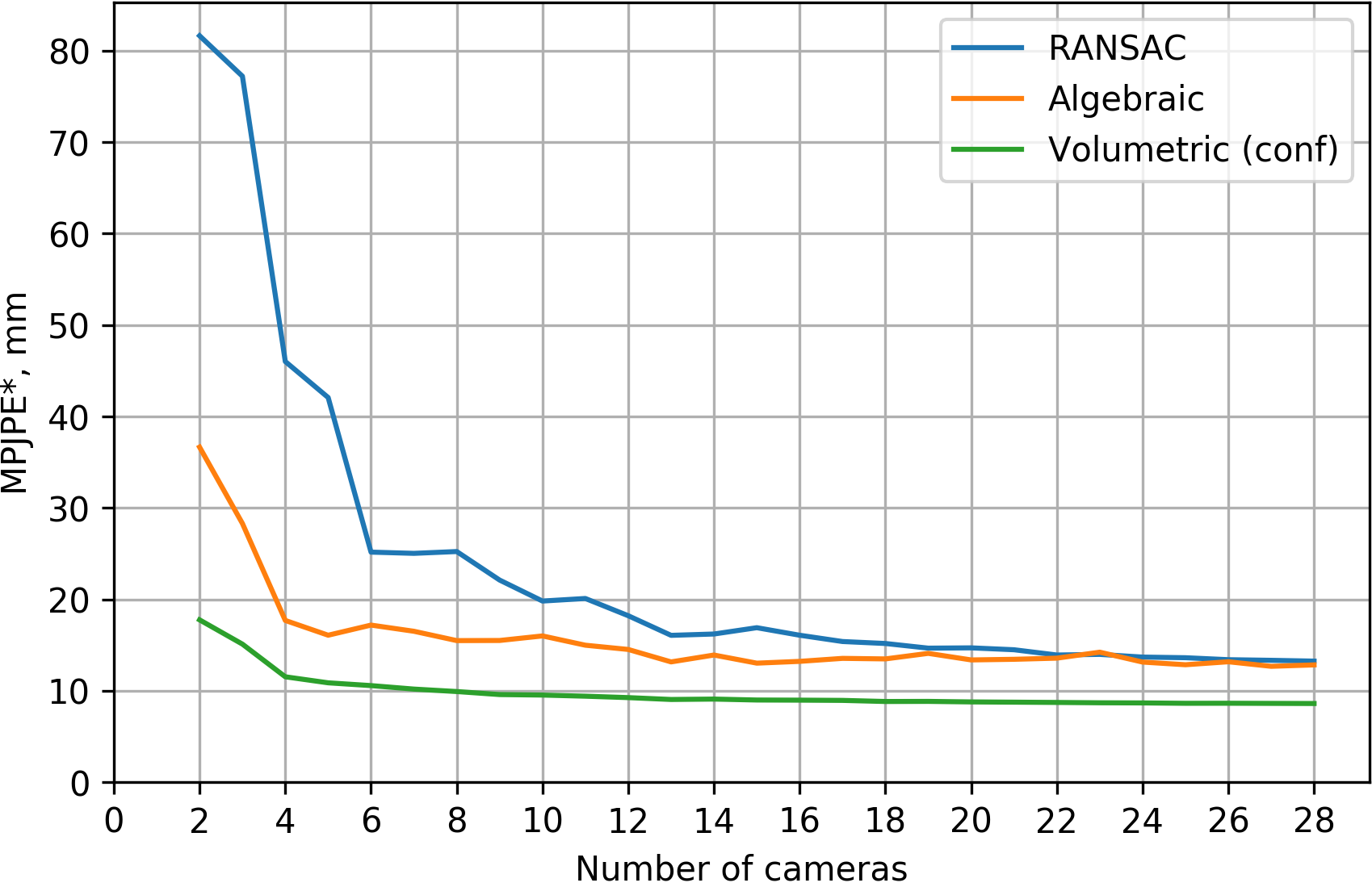
- CMU Panoptic dataset contains ~30 cameras, so we measured quality of our methods in relation to the number of cameras
MPJPE relative to pelvis [4 cameras]:
| MPJPE, mm | |
|---|---|
| RANSAC (our implementation) | 39.5 |
| Ours, algebraic | 21.3 |
| Ours, volumetric | 13.7 |

Transfer from CMU Panoptic to Human3.6M
We demonstrate that the learnt model is able to transfer between different coloring and camera setups without any finetuning (see video demonstration).

Overview
Our approaches assume we have synchronized video streams from cameras with known projection matrices capturing performance of a single person in the scene. We aim at estimating the global 3D positions of a fixed set of human joints with indices .
Note: Here we present only short overview of our methods. Please refer to our paper [cite] for more details.
Algebraic
Our first approach is based on algebraic triangulation with learned confidences.

-
2D backbone produces the joints’ heatmaps and camera-joint confidences .
-
The 2D positions of the joints are inferred from 2D joint heatmaps by applying soft-argmax (with inverse temperature parameter ):
-
The 2D positions together with the confidences are passed to the algebraic triangulation module which solves triangulation problem in the form of system of weighted linear equations:
where - vector of confidences for joint , - matrix combined of 2D joint coordinates and camera parameters (see details in [1]) and - target 3D position of joint .
All blocks allow backpropagation of the gradients, so the model can be trained end-to-end.
Volumetric
Our second approach is based on volumetric triangulation.

-
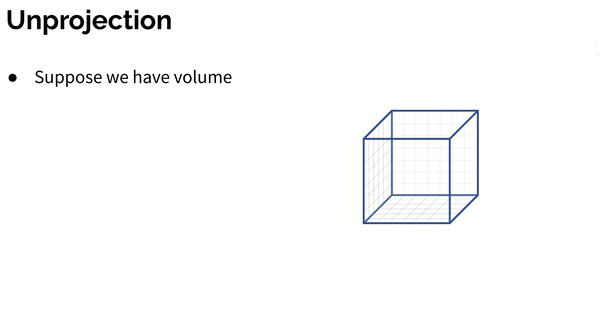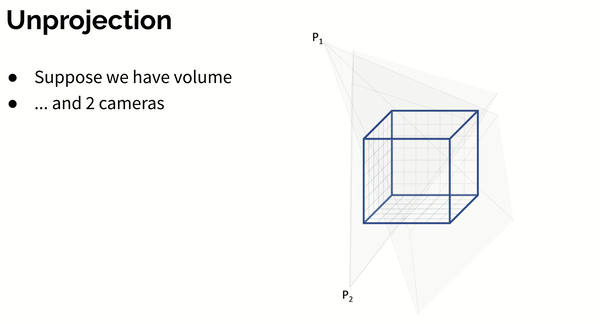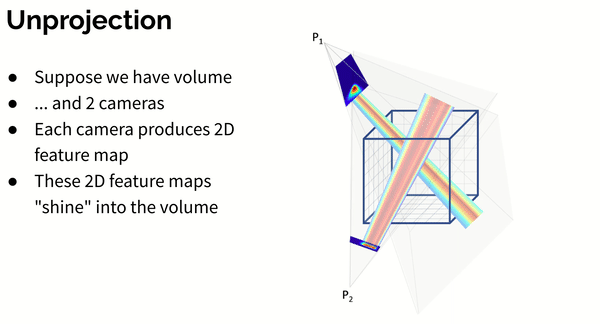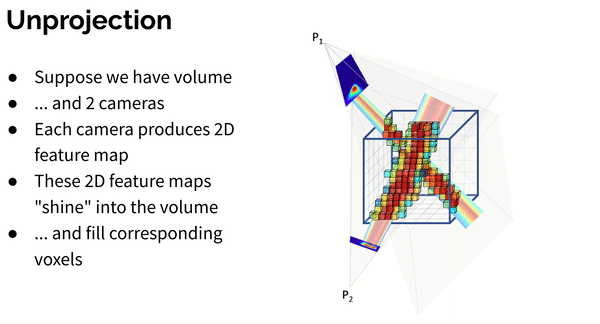
The 2D backbone produces intermediate feature maps (note, that unlike the first model, feature maps don’t have to be interpretable).
-
Then feature maps are unprojected into a volume with a per-view aggregation (see animation below):
where - absolute coordinates of each voxel, - projection matrix of camera . Operation denotes bilinear sampling.
-
The volume is passed to a 3D convolutional neural network that outputs the interpretable 3D heatmaps .
-
The output 3D positions of the joints are inferred from 3D joint heatmaps by computing soft-argmax:
Unlike the algebraic method, volumetric has 3D convolutional neural network, which is able to model human pose prior. Volumetric model is also fully differentiable and can be trained end-to-end.
Here’s an animation showing how unprojection works for 2 cameras:
Human3.6M erroneous annotations
There are some 3D pose annotation errors in the Human3.6M dataset. For subject S9, actions:
- Greeting
- SittingDown
- Waiting
Interestingly, the error is nullified when the pelvis is subtracted (as done for monocular methods), however, to make the results for the multi-view setup interpretable we must exclude these scenes from the evaluation.
Here is the example of erroneous 3D pose annotations (S9, “Greeting”):
BibTeX
@inproceedings{iskakov2019learnable,
title={Learnable Triangulation of Human Pose},
author={Iskakov, Karim and Burkov, Egor and Lempitsky, Victor and Malkov, Yury},
booktitle = {International Conference on Computer Vision (ICCV)},
year={2019}
}
References
- [1] R. Hartley and A. Zisserman. Multiple view geometry in computer vision.
- [2] C. Ionescu, D. Papava, V. Olaru, and C. Sminchisescu. Human3.6m: Large scale datasets and predictive methods for 3d human sensing in natural environments.
- [3] H. Joo, T. Simon, X. Li, H. Liu, L. Tan, L. Gui, S. Banerjee, T. S. Godisart, B. Nabbe, I. Matthews, T. Kanade,S. Nobuhara, and Y. Sheikh. Panoptic studio: A massively multiview system for social interaction capture.
- [4] D. Tome, M. Toso, L. Agapito, and C. Russell. Rethinking Pose in 3D: Multi-stage Refinement and Recovery for Markerless Motion Capture.
- [5] A. Kadkhodamohammadi and N. Padoy. A generalizable approach for multi-view 3D human pose regression.
- [6] X. Sun, B. Xiao, S. Liang, and Y. Wei. Integral human pose regression.
- [7] J. Martinez, R. Hossain, J. Romero, and J. J. Little. A simple yet effective baseline for 3d human pose estimation.
- [8] G. Pavlakos, X. Zhou, K. G. Derpanis, and K. Daniilidis. Harvesting multiple views for marker-less 3D human pose annotations.